Oozie: Guiding Your Big Data Workflows With Ease
When it comes to handling big collections of information, especially in systems like Hadoop, keeping everything organized can be a real task. It's like trying to get a large group of people to do different things in a certain order, all at the right moment. That's where something called oozie steps in, offering a helpful way to manage these complex sequences of actions. It's a tool that lets you set up and run jobs, making sure they happen in the right sequence, even if some of them depend on others finishing first.
So, what exactly does oozie do for you? Well, it acts as a kind of central manager for your data processing steps. Imagine you have several tasks that need to run one after another, or perhaps some tasks that can only begin once others are completely done. Oozie helps you define these connections and then takes care of running them. It's designed to be a system that you can count on, very flexible, and able to grow as your needs get bigger, too.
For anyone working with data, especially those dealing with Hadoop, understanding oozie can make a big difference. It helps bring order to what might otherwise be a very chaotic process. This post will walk you through what oozie is all about, how it helps manage big data jobs, and how you might get started with it. It's a pretty useful system, you know, for keeping things running smoothly.
Table of Contents
- What Exactly is Oozie?
- Why Oozie Matters for Data Pros
- Getting Started with Oozie: Your First Steps
- Working with Oozie: Daily Tasks and Insights
- Oozie in the Larger World of Data Management
- Frequently Asked Questions About Oozie
What Exactly is Oozie?
Oozie, at its core, is a specialized kind of system. It's a server-based workflow engine, which basically means it's a program that lives on a server and helps run a series of connected tasks. This system is very good at running jobs that involve Hadoop's MapReduce and Pig technologies, too. Think of it as a conductor for an orchestra, where each musician is a data processing task, and oozie makes sure they all play their part at the right time, as a matter of fact.
The system is known for being very dependable, and it can handle a lot of work. It's also quite flexible, allowing for changes and additions as your data processing needs grow. This makes it a rather useful tool for organizations that deal with huge amounts of information and need to process it in a structured way. It really helps keep things orderly, you know.
My text describes oozie as a "scalable, reliable and extensible system." This means it can grow with your data, you can count on it to do its job, and it can be changed or added to easily. It's not just a simple script runner; it's a full-fledged system built to manage complicated data pipelines in a big data environment, apparently.
Why Oozie Matters for Data Pros
For people who build and manage data systems, oozie solves a number of significant problems. Imagine trying to manually start dozens of data jobs every day, making sure each one finishes before the next one starts. That would be a huge headache, and honestly, prone to many errors. Oozie takes that manual effort away, offering a way to automate these sequences, which is quite helpful.
My text mentions that "Developers interested in getting more involved with oozie may join the mailing lists, report bugs, retrieve code from the version." This points to a community around oozie, suggesting it's a tool that's actively supported and developed. Being able to connect with others who use the system, share experiences, and get help is a big plus for anyone working with it, you know.
The ability to automate complex job flows means less human error and more efficient use of computing resources. It also provides a clear picture of how data is moving through different processing steps. For data professionals, this means more time spent on analyzing data and less time on babysitting jobs, which is a pretty good deal, you see.
Getting Started with Oozie: Your First Steps
So, you're curious about trying out oozie for yourself? It's a fairly straightforward process to get it up and running, though it does involve a few steps. The initial part is getting the software itself, and then you'll set it up in your system. It's not overly complicated, but it does require attention to detail, too.
Finding and Getting Oozie
My text tells us how to begin: "Building oozie download a source distribution of oozie from the “releases” drop down menu on the oozie site." This means you'll head over to the official oozie website, look for the section where they list different versions, and pick the one you want. It's typically a compressed file, like a tar.gz archive, that you'll bring down to your computer, apparently.
Finding the right release is important. You'll want to make sure it's compatible with your existing Hadoop setup, for instance. Checking the documentation on the oozie site alongside the download links can help ensure you pick a good fit for your environment. It's a pretty simple process, really, just like getting any other software package, you know.
Setting Up Oozie for Use
Once you have the downloaded file, the next step is to prepare it for use. My text advises to "Expand the source distribution tar.gz and change directories into." This means you'll uncompress the file, which will create a new folder, and then you'll go inside that folder. This is where all the oozie program files live, basically.
After you're in the right directory, you'll likely need to do some configuration. The documentation that comes with the distribution will guide you through setting up things like database connections and other system specifics. My text also mentions, "The oozied.sh script should be used instead," indicating there's a specific script for starting the oozie server. This script helps get the whole system running correctly, so it's quite important.
It's also worth noting a point my text brings up: "Since oozie will execute the shell command into a hadoop compute node, the default installation of utility in the compute node might not be fixed." This is a heads-up that when oozie runs tasks on your Hadoop cluster, you might need to make sure all the necessary tools are installed and working on those individual machines. It's a common consideration for distributed systems, honestly, making sure everything is ready to go where the work happens.
Working with Oozie: Daily Tasks and Insights
Once oozie is set up, you'll interact with it to manage your data jobs. This involves submitting new workflows, checking on existing ones, and keeping an eye on the system's overall health. It's a very interactive process, allowing you to stay on top of your data processing activities, you know.
The Oozie Command Line Helper
My text states, "Introduction oozie provides a command line utility, oozie , to perform job and admin tasks." This is your primary way of talking to oozie. It's a tool you use from your computer's terminal, typing in commands to tell oozie what you want it to do. This utility is quite powerful, letting you manage everything from submitting a new job to getting details about one that's already running, as a matter of fact.
The command line tool is how "The oozie cli interacts with" the main oozie server. It sends your requests to the server, and the server sends back information. This interaction is key to managing your workflows effectively. Learning the various commands for this utility is a big step in becoming comfortable with oozie, you see.
Checking Oozie's Pulse
Keeping an eye on oozie's health is also important. My text mentions, "This endpoint is for obtaining oozie system status and configuration information." This means there's a specific place or command you can use to check if oozie is running well, what its settings are, and if there are any problems. It's like taking the system's temperature, basically.
Regularly checking the system status helps you catch potential issues before they become bigger problems. It ensures that your data workflows continue to run without unexpected interruptions. This kind of monitoring is a good practice for any critical system, and oozie provides the means to do it easily, too.
Oozie in the Larger World of Data Management
Oozie has been a foundational tool for many years in the big data space, especially for those relying on Hadoop. While new tools come along all the time, oozie continues to be a very relevant choice for orchestrating complex data pipelines. Its focus on reliability and scalability means it still meets the needs of many organizations, as a matter of fact.
The system's ability to handle MapReduce and Pig jobs specifically makes it a natural fit for existing Hadoop infrastructures. It helps bridge the gap between individual data processing steps and a complete, automated data flow. This kind of automation is a critical piece of modern data operations, you know, ensuring that data is processed consistently and efficiently.
Even today, with many different big data technologies available, oozie's straightforward approach to workflow management remains valuable. It provides a clear way to define and run sequences of jobs, which is always going to be a need when dealing with large datasets. It's a testament to its design that it continues to be used and discussed within the data community, which is pretty neat.
For those looking to deepen their knowledge, the official Apache Oozie website is a fantastic resource. You can find detailed documentation, community forums, and the latest releases there. It's a great place to get more information directly from the source, if you're interested in that sort of thing. Visit the Apache Oozie site for more.
Learn more about oozie on our site, and you can also explore other related topics here to expand your understanding of data systems.
Frequently Asked Questions About Oozie
What is Oozie used for?
Oozie is primarily used for managing and running sequences of data processing jobs, especially those that involve Hadoop technologies like MapReduce and Pig. It helps automate complex workflows, ensuring that tasks run in the correct order and at the right time. It's a way to bring structure to your big data operations, basically.
How do I run a job in Oozie?
To run a job in oozie, you typically use its command line utility. You define your workflow in an XML file, which tells oozie the steps to take and their dependencies. Then, you use a command like `oozie job -run -config your_workflow.xml` to submit that workflow to the oozie server. The server then takes over and executes the tasks, as a matter of fact.
Is Oozie still relevant for big data?
Yes, oozie remains quite relevant for big data, particularly for environments that heavily use Hadoop and its ecosystem. While newer tools have emerged, oozie's proven reliability, scalability, and focus on Hadoop-specific job types make it a valuable choice for many organizations. It continues to be a solid solution for automating complex data pipelines, you know, even in today's data landscape.

Oozie Photos, Download The BEST Free Oozie Stock Photos & HD Images
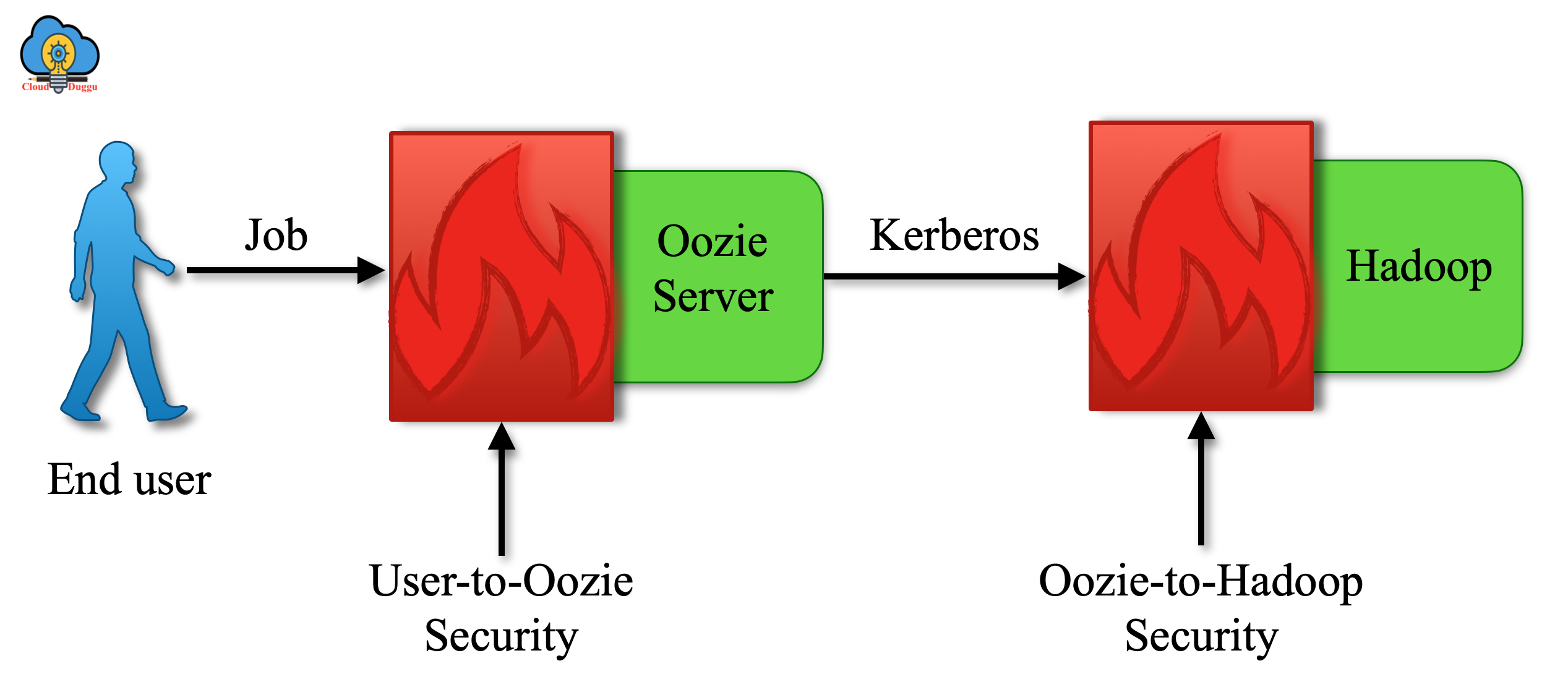
Apache Oozie Security Tutorial | CloudDuggu
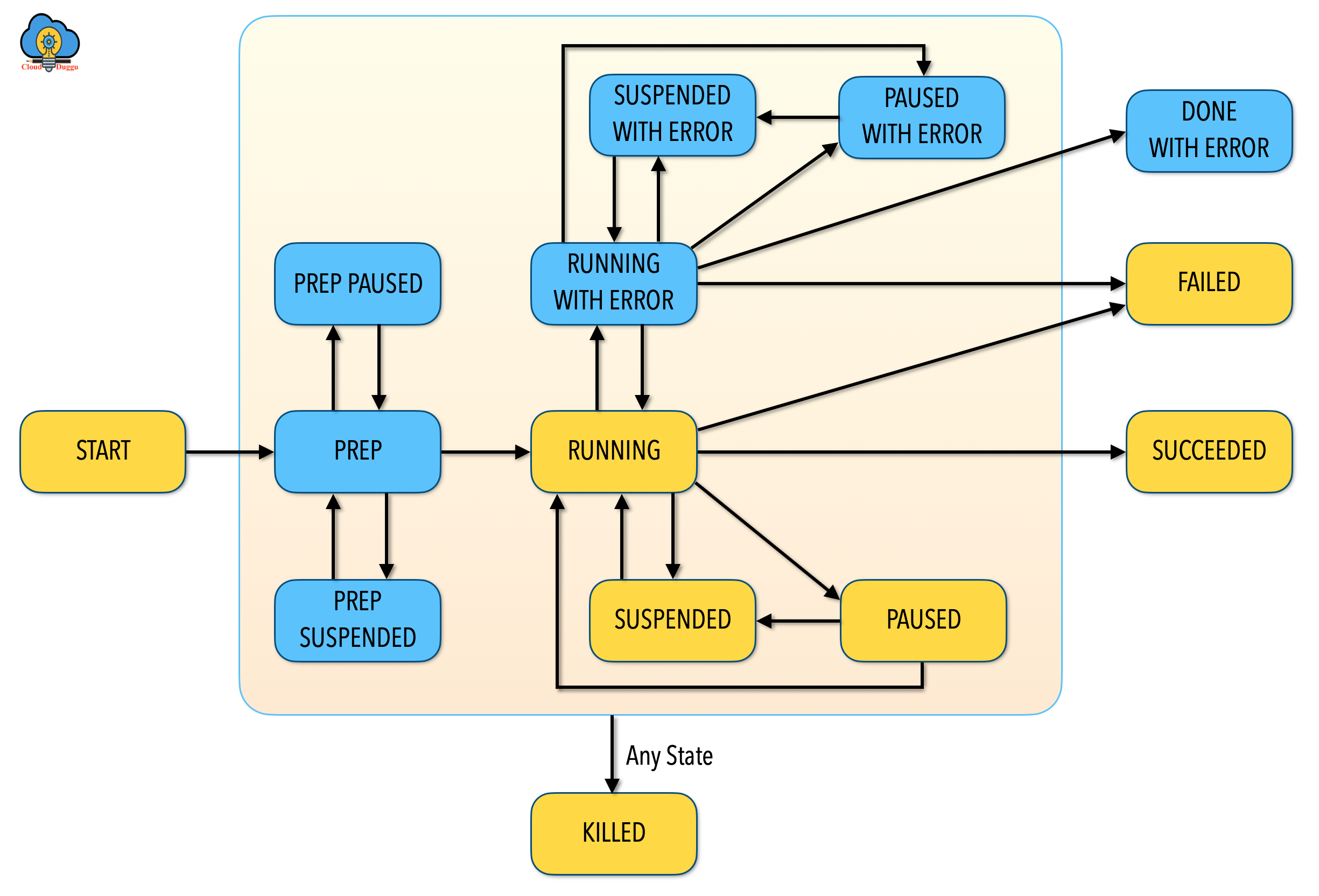
Apache Oozie Bundle Tutorial | CloudDuggu
